The order-finding problem is a fundamental problem that plays a central role in several quantum algorithms; in particular, it underlies Shor’s celebrated factoring algorithm. Classically, order-finding is hard—no efficient classical algorithm is known—but quantum computers can solve it efficiently. Efficiently determining the order of an integer modulo  allows integers to be factored in polynomial time, which would compromise RSA encryption, as we will discuss in the subsequent sections.
allows integers to be factored in polynomial time, which would compromise RSA encryption, as we will discuss in the subsequent sections.
The order-finding problem is defined rigorously as follows:
At first glance, this definition may appear somewhat abstract.
Do not worry—shortly, we will unpack each of the mathematical ingredients and illustrate their meaning with concrete examples.
The quantum algorithm for order-finding exploits the periodic structure of the function

which is periodic with period exactly  . By preparing a quantum superposition over all possible exponents and applying the quantum phase estimation algorithm to the unitary operator
. By preparing a quantum superposition over all possible exponents and applying the quantum phase estimation algorithm to the unitary operator

we obtain an efficient quantum procedure that succeeds with high probability.
Preliminaries of Modular Arithmetic
Before presenting the complete quantum algorithm, let us first review a few essential results from number theory. This section may appear somewhat technical compared to others; if you prefer not to delve into the details, simply remember that for coprime integers  and , there exists a positive order , and the function in Eq.(1) is periodic and turn to the next section.
and , there exists a positive order , and the function in Eq.(1) is periodic and turn to the next section.
An integer  is called a prime number if it has no nontrivial divisors; for example,
is called a prime number if it has no nontrivial divisors; for example,  are prime numbers. Otherwise, is called a composite number. We use
are prime numbers. Otherwise, is called a composite number. We use 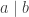 to denote that
to denote that  is divisible by , for instance
is divisible by , for instance  ,
,  . Similarly,
. Similarly,  means that does not divide , for example
means that does not divide , for example  .
.
Every integer can be uniquely expressed as a product of prime powers:

where  are distinct prime numbers and
are distinct prime numbers and  are positive integers. This result is known as the Fundamental Theorem of Arithmetic.
are positive integers. This result is known as the Fundamental Theorem of Arithmetic.
To obtain the prime factorization of a given number , one typically follows these steps:
- Divide by
 repeatedly until the quotient is no longer divisible by .
repeatedly until the quotient is no longer divisible by .
Let 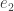 be the number of times we divide by , and denote the resulting quotient by
be the number of times we divide by , and denote the resulting quotient by  , for which
, for which  .
.
- For the quotient
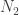 , proceed with the next prime,
, proceed with the next prime,  , and divide repeatedly until the quotient is no longer divisible by .
, and divide repeatedly until the quotient is no longer divisible by .
Let 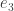 be the number of divisions, and denote the resulting quotient by
be the number of divisions, and denote the resulting quotient by  .
.
- Continue in this manner with successive primes
 until the quotient becomes
until the quotient becomes  .
.
Exercise. Decompose  into its prime factors:
into its prime factors:  .
.
The key operation we will use is modular arithmetic.
In everyday life we count linearly: 1, 2, 3, …, but in modular arithmetic we count on a circle.
Take a clock that shows only 12 hours. When the hand reaches 12, it jumps back to 0.
Mathematically, we say time is measured modulo 12.
This simple idea—wrapping around after a fixed modulus —is crucial in number theory and its applications in modern public-key cryptography.
Definition (Congruence) Fix an integer  , called the modulus.
, called the modulus.
Two integers and are congruent modulo if their difference is a multiple of :

We read  as “ is congruent to modulo ”.
as “ is congruent to modulo ”.
The congruence class of is usually represented by its smallest non-negative residue:

It is also convenient to use ![[a]](https://s0.wp.com/latex.php?latex=%5Ba%5D&bg=ffffff&fg=333333&s=0&c=20201002) to denote the congruence class whenever there is no ambiguity about the modulus.
to denote the congruence class whenever there is no ambiguity about the modulus.
Example. Let 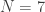 . We have
. We have  . Then
. Then  and
and  . The congruence class
. The congruence class ![[0]](https://s0.wp.com/latex.php?latex=%5B0%5D&bg=ffffff&fg=333333&s=0&c=20201002) consists of
consists of  , the congruence class
, the congruence class ![[1]](https://s0.wp.com/latex.php?latex=%5B1%5D&bg=ffffff&fg=333333&s=0&c=20201002) consists of
consists of  , and
, and ![[2]](https://s0.wp.com/latex.php?latex=%5B2%5D&bg=ffffff&fg=333333&s=0&c=20201002) consists of
consists of  , etc.
, etc.
The order-finding problem considers the modular exponentiation for given integers and :

The remainder can take values in  :
:



However, not all values of  are necessarily attainable.
are necessarily attainable.
For example, let 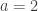 and
and  . We find that
. We find that






We observe a repeating pattern. In this case, the residues  , , and
, , and 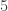 never appear.
never appear.
Note also that  for any integers and . Hence, the order of modulo is defined as the smallest positive integer such that
for any integers and . Hence, the order of modulo is defined as the smallest positive integer such that  . However, we must still ensure that such an order actually exists. In fact, if
. However, we must still ensure that such an order actually exists. In fact, if  , then no positive integer satisfies . This can be seen in the previous example with and , where the sequence never returns to modulo
, then no positive integer satisfies . This can be seen in the previous example with and , where the sequence never returns to modulo  .
.
Exercise. Let and . Then the only integer satisfying
is 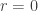 .
.
Proof. Suppose there exists an integer such that .
Then divides  , so in particular
, so in particular
 .
.
Since  , we also have
, we also have  , and therefore
, and therefore
 ,
,
which contradicts 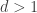 . Hence no such
. Hence no such  exists.
exists.
For , the convention  gives
gives

trivially. Thus is the only solution ∎.
In Shor’s algorithm, we either assume  , or first compute the greatest common divisor classically, which already yields a nontrivial factor of if .
, or first compute the greatest common divisor classically, which already yields a nontrivial factor of if .
Another useful concept we will use is Euler’s Totient function: 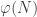 counts the number of integers
counts the number of integers  coprime to .
coprime to .
For example,  ,
,  ,
,  ,
,  , etc.
, etc.
For fixed , consider  .
.
We call  invertible if there exists an integer
invertible if there exists an integer  such that
such that  .
.
Proposition (Bézout’s Identity). Let and be integers with greatest common divisor  . Then there exist integers
. Then there exist integers  and
and  such that
such that
 .
.
Moreover, the integers of the form  are exactly the multiples of
are exactly the multiples of  .
.
The set is not a group under multiplication modulo in general. We denote by  the set of invertible elements, which indeed forms a group. By Bézout’s identity,
the set of invertible elements, which indeed forms a group. By Bézout’s identity,  consists of all integers coprime to , and this group has order
consists of all integers coprime to , and this group has order  , where
, where  denotes Euler’s totient function.
denotes Euler’s totient function.
From a group-theoretic perspective, for any  , there exists a positive integer such that
, there exists a positive integer such that
.
Since must be invertible, it follows that . In the multiplicative group , the order of any element divides the order of the group, that is,
 .
.
Theorem (Euler’s Theorem). If , then

and hence the order of modulo divides .
By Euler’s theorem, for integers and with , there always exists a positive integer such that

The order  always satisfies
always satisfies  .
.
Since in the cyclic subgroup generated by ![[a] \in \mathbf{Z}_N^{\times}](https://s0.wp.com/latex.php?latex=%5Ba%5D+%5Cin+%5Cmathbf%7BZ%7D_N%5E%7B%5Ctimes%7D&bg=ffffff&fg=333333&s=0&c=20201002) we have
we have
![{[a^0], [a^1], [a^2], \dots, [a^{r-1}]}, \quad \text{with } [a^r] = [a^0] = [1],](https://s0.wp.com/latex.php?latex=%7B%5Ba%5E0%5D%2C+%5Ba%5E1%5D%2C+%5Ba%5E2%5D%2C+%5Cdots%2C+%5Ba%5E%7Br-1%7D%5D%7D%2C+%5Cquad+%5Ctext%7Bwith+%7D+%5Ba%5Er%5D+%3D+%5Ba%5E0%5D+%3D+%5B1%5D%2C&bg=ffffff&fg=333333&s=0&c=20201002)
the sequence  is periodic with period equal to the order :
is periodic with period equal to the order :






Thus, the sequence repeats with period .
Example. Set and . We have  as:
as:









We see that the order is  .
.
Quantum Order-Finding Algorithm
The quantum order-finding algorithm can be divided into two main steps:
- Encode the order into the phase of an eigenvalue of a suitable unitary operator, thereby reducing the order-finding problem to a quantum phase estimation problem.
- Recover the order from the estimated phase
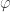 using the method of continued fractions.
using the method of continued fractions.
Let us first examine how to encode the order into the phase of a unitary operator.
Fix integers and such that .
Define the unitary operator  acting on computational basis states
acting on computational basis states  by
by

We will see that the order can be mapped to the phase of an eigenvalue of .
Proposition. Let and let be an integer coprime to .
The operator on  defined by
defined by
is unitary.
Proof. Since , multiplication by modulo defines a bijection on the set  .
.
Thus merely permutes the computational basis  . Any permutation of an orthonormal basis extends to a unitary operator, so is unitary.
. Any permutation of an orthonormal basis extends to a unitary operator, so is unitary.
Alternatively, suppose  . Then
. Then
 .
.
Because , we may cancel (more precisely, multiply both sides by the modular inverse of modulo ) to obtain
 .
.
Since  , the only possibility is
, the only possibility is  , so
, so  .
.
Thus is injective on a basis of .
Being an isometry that maps a basis to a basis, it is unitary ∎.
Proposition. Let be the order of modulo , i.e., the smallest positive integer such that
.
For each  , define the state
, define the state

Then, for each ,  is an eigenstate of with eigenvalue
is an eigenstate of with eigenvalue
 .
.
Proof. Apply to :


Reindex the sum by letting  :
:



The sum now runs from 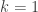 to , but the
to , but the  term is
term is

while the 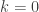 term in the original definition of is
term in the original definition of is

Thus the missing term is exactly replaced by the term, and we obtain

This holds for every ∎.
Now the procedure becomes “straightforward”. We apply quantum phase estimation (see this post) to the operators  with the eigenstate , which yields the phases
with the eigenstate , which yields the phases

The output of the phase estimation algorithm is thus

represented as binary numbers. A classical algorithm called continued fractions can be applied to obtain the order .


 , where
, where  is the initial state and each
is the initial state and each  denotes a completely positive trace-preserving (CPTP) map describing the evolution from
denotes a completely positive trace-preserving (CPTP) map describing the evolution from  to
to  . The system state at an intermediate time
. The system state at an intermediate time  is then obtained recursively as
is then obtained recursively as  .
.
![= \mathrm{Tr}[ \Pi_{a_n|A_n}^{t_n} \mathcal{E}_{t_n \leftarrow t_{n-1}}(\cdots \Pi_{a_1|A_1}^{t_1}( \mathcal{E}_{t_1 \leftarrow t_0}( \Pi_{a_0|A_0}^{t_0} \rho_{t_0} \Pi_{b_0|B_0}^{t_0})) \Pi_{b_1|B_1}^{t_1} \cdots) \Pi_{b_n|B_n}^{t_n}]](https://s0.wp.com/latex.php?latex=%3D+%5Cmathrm%7BTr%7D%5B+%5CPi_%7Ba_n%7CA_n%7D%5E%7Bt_n%7D+%5Cmathcal%7BE%7D_%7Bt_n+%5Cleftarrow+t_%7Bn-1%7D%7D%28%5Ccdots+%5CPi_%7Ba_1%7CA_1%7D%5E%7Bt_1%7D%28+%5Cmathcal%7BE%7D_%7Bt_1+%5Cleftarrow+t_0%7D%28+%5CPi_%7Ba_0%7CA_0%7D%5E%7Bt_0%7D+%5Crho_%7Bt_0%7D+%5CPi_%7Bb_0%7CB_0%7D%5E%7Bt_0%7D%29%29+%5CPi_%7Bb_1%7CB_1%7D%5E%7Bt_1%7D+%5Ccdots%29+%5CPi_%7Bb_n%7CB_n%7D%5E%7Bt_n%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002)
 and
and  . These two distributions are related by complex conjugation, reflecting the intrinsic temporal structure encoded in the doubled formalism. The temporal Margenau-Hill (MH) quasiprobability distribution is defined as real part of the temporal KD distribution.
. These two distributions are related by complex conjugation, reflecting the intrinsic temporal structure encoded in the doubled formalism. The temporal Margenau-Hill (MH) quasiprobability distribution is defined as real part of the temporal KD distribution.![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) . This phenomenon reflects the intrinsically quantum nature of multi-time processes, in direct analogy with the negativity and nonclassical features of the spatial KD quasiprobability distribution. Using the Heisenberg picture, we provide a general and unified explanation for the origin of this quantumness.
. This phenomenon reflects the intrinsically quantum nature of multi-time processes, in direct analogy with the negativity and nonclassical features of the spatial KD quasiprobability distribution. Using the Heisenberg picture, we provide a general and unified explanation for the origin of this quantumness.

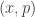 specifies the position and momentum of a particle, and our uncertainty about the system is encoded in a genuine probability density
specifies the position and momentum of a particle, and our uncertainty about the system is encoded in a genuine probability density  . Such distributions are always non-negative real functions and satisfy a normalization condition, reflecting the familiar rules of classical probability theory. All classical observables are functions on phase space,
. Such distributions are always non-negative real functions and satisfy a normalization condition, reflecting the familiar rules of classical probability theory. All classical observables are functions on phase space,  , and their expectation values are given by
, and their expectation values are given by .
. (or, more generally, a density operator), which does not represent a probability distribution in phase space. While
(or, more generally, a density operator), which does not represent a probability distribution in phase space. While  gives the probability density for position and
gives the probability density for position and  gives the probability density for momentum, there is no single function that simultaneously assigns probabilities to both position and momentum. This obstruction is not merely technical but fundamental, rooted in the noncommutativity of quantum observables and formalized by the Heisenberg uncertainty principle.
gives the probability density for momentum, there is no single function that simultaneously assigns probabilities to both position and momentum. This obstruction is not merely technical but fundamental, rooted in the noncommutativity of quantum observables and formalized by the Heisenberg uncertainty principle. -function and the Glauber–Sudarshan
-function and the Glauber–Sudarshan  -function, widely used in quantum optics.
-function, widely used in quantum optics. , bras
, bras  , kets
, kets  ), but I will explain as we go.
), but I will explain as we go. and
and 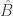 be two Hermitian observables with eigenbases
be two Hermitian observables with eigenbases  and
and  , respectively, assuming a finite-dimensional Hilbert space of dimension
, respectively, assuming a finite-dimensional Hilbert space of dimension 
 is the overlap between the eigenvectors.
is the overlap between the eigenvectors. and
and  , it can also be written as:
, it can also be written as:
 ):
):
 observables):
observables): 
 :
: 


 are non-zero, the density operator can be recovered from the KD distribution:
are non-zero, the density operator can be recovered from the KD distribution: 

 for states that behave classically with respect to the chosen observables.
for states that behave classically with respect to the chosen observables.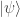 of a unitary operator
of a unitary operator  ,
,
 for convenience. Kitaev’s idea is to encode the phase information into the amplitudes of certain superposition states and extract
for convenience. Kitaev’s idea is to encode the phase information into the amplitudes of certain superposition states and extract  using the interferometric scheme.
using the interferometric scheme.








 cannot distinguish between
cannot distinguish between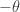 .
. to resolve this ambiguity.
to resolve this ambiguity.

 on the control qubit prior to the controlled-
on the control qubit prior to the controlled-



 taking values in
taking values in  .
. and
and  .
.
 time on a quantum computer. This is exponentially faster than the best classical algorithms, such as the general number field sieve, which runs in sub-exponential time
time on a quantum computer. This is exponentially faster than the best classical algorithms, such as the general number field sieve, which runs in sub-exponential time  , where
, where  .
.
 , which she keeps secret. She computes
, which she keeps secret. She computes  and publishes
and publishes  , which is required to be relatively prime to
, which is required to be relatively prime to  , that is,
, that is,  . Alice then computes the multiplicative inverse of
. Alice then computes the multiplicative inverse of  modulo
modulo 
 with
with  . He encrypts it as
. He encrypts it as
 , Alice decrypts it using
, Alice decrypts it using
 .
. . Hence
. Hence![(m^e)^{d} = m \bigl[ m^{k(q-1)} \bigr]^{p-1}](https://s0.wp.com/latex.php?latex=%28m%5Ee%29%5E%7Bd%7D+%3D+m+%5Cbigl%5B+m%5E%7Bk%28q-1%29%7D+%5Cbigr%5D%5E%7Bp-1%7D&bg=ffffff&fg=333333&s=0&c=20201002) .
.![\bigl[ m^{k(q-1)} \bigr]^{p-1} \equiv 1 \pmod{p}](https://s0.wp.com/latex.php?latex=%5Cbigl%5B+m%5E%7Bk%28q-1%29%7D+%5Cbigr%5D%5E%7Bp-1%7D+%5Cequiv+1+%5Cpmod%7Bp%7D&bg=ffffff&fg=333333&s=0&c=20201002) .
. .
.![\bigl[ m^{k(p-1)} \bigr]^{q-1} \equiv 1 \pmod{q}](https://s0.wp.com/latex.php?latex=%5Cbigl%5B+m%5E%7Bk%28p-1%29%7D+%5Cbigr%5D%5E%7Bq-1%7D+%5Cequiv+1+%5Cpmod%7Bq%7D&bg=ffffff&fg=333333&s=0&c=20201002)
 if
if  by considering several cases.
by considering several cases. ,
,![\bigl[m^{k(p-1)}\bigr]^{q-1} \equiv 1 \pmod{q}](https://s0.wp.com/latex.php?latex=%5Cbigl%5Bm%5E%7Bk%28p-1%29%7D%5Cbigr%5D%5E%7Bq-1%7D+%5Cequiv+1+%5Cpmod%7Bq%7D&bg=ffffff&fg=333333&s=0&c=20201002) .
. .
. ,
, and
and  , with
, with  , then
, then  . In particular, if
. In particular, if  and
and  implies
implies  .
. .
. , where
, where  for random choices) is as follows:
for random choices) is as follows: and compute
and compute  :
: , then
, then 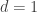 , continue.
, continue. .
. :
: , return to the first step.
, return to the first step. , proceed.
, proceed. ,
,  .
. .
. (the cases explicitly filtered out by the algorithm). Since
(the cases explicitly filtered out by the algorithm). Since  ,
, , or equivalently,
, or equivalently, .
. can be distributed in only four logical ways:
can be distributed in only four logical ways: and
and 
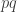 divides
divides  and
and  (or vice versa).
(or vice versa). .
.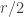 , which is impossible unless
, which is impossible unless  .
. .
. . Compute
. Compute  .
. .
.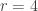 , since
, since  .
. .
. , which is one factor of
, which is one factor of 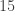 .
. , and
, and  , which is the other factor.
, which is the other factor. .
.
 queries to search an unsorted database of
queries to search an unsorted database of 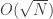 queries by exploiting quantum parallelism and amplitude amplification.
queries by exploiting quantum parallelism and amplitude amplification.
 , where
, where 
 for the marked item
for the marked item 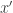 and
and  for all other items$, the task is to find the marked elements
for all other items$, the task is to find the marked elements  and
and 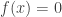 for all other items.
for all other items. , which is a unitary operation that flips the sign of the amplitude of the marked state:
, which is a unitary operation that flips the sign of the amplitude of the marked state:
 corresponds to the binary string
corresponds to the binary string  , we define the oracle
, we define the oracle


 , so its phase is flipped:
, so its phase is flipped:  For all unmarked elements,
For all unmarked elements,  items, of which
items, of which 


 and
and  :
:

 corresponding to the unmarked states is much larger than the coefficient
corresponding to the unmarked states is much larger than the coefficient  associated with the marked states. Consequently, the initial state
associated with the marked states. Consequently, the initial state 
 . Geometrically, this can be viewed as a reflection about the state
. Geometrically, this can be viewed as a reflection about the state  ,
, ,
, ,
, ,
, and
and  are the coefficients of
are the coefficients of  is orthogonal to
is orthogonal to  . Acting with
. Acting with  yields
yields ,
, .
. ,
,  . Applying the oracle
. Applying the oracle  toward
toward  therefore increases this angle by
therefore increases this angle by  performs the rotation illustrated in Fig. 2. Show explicitly that the Grover iteration acts as a rotation matrix in the basis
performs the rotation illustrated in Fig. 2. Show explicitly that the Grover iteration acts as a rotation matrix in the basis  .
. qubits in the state
qubits in the state  .
. to obtain the equal superposition
to obtain the equal superposition .
.
 . Initially, all basis states have amplitude
. Initially, all basis states have amplitude  . After applying the oracle and the diffusion operator, the amplitude of the marked state increases, while the amplitudes of unmarked states decrease.
. After applying the oracle and the diffusion operator, the amplitude of the marked state increases, while the amplitudes of unmarked states decrease. . After
. After  .
. ,
,

 be a function from n-bit strings to a single bit,
be a function from n-bit strings to a single bit,  , such that there exists a secret bit string
, such that there exists a secret bit string  with the property that, for every input
with the property that, for every input  ,
,  , where the dot product is defined by
, where the dot product is defined by  , with
, with  and
and  . The task is to determine the secret string
. The task is to determine the secret string  using as few queries to
using as few queries to  , compute
, compute  for all
for all  . As an example, take
. As an example, take  . Then
. Then  The function defined by
The function defined by  is an example of a function satisfying the Bernstein–Vazirani property.
is an example of a function satisfying the Bernstein–Vazirani property.
 , i.e. it obeys
, i.e. it obeys
 has the Bernstein–Vazirani form, find explicit
has the Bernstein–Vazirani form, find explicit 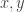 for which
for which
 and
and  . Then
. Then  , while
, while
 , showing the required contradiction. ∎
, showing the required contradiction. ∎




 ,
, . If we can prepare the corresponding state, applying Hadamard gates directly yields
. If we can prepare the corresponding state, applying Hadamard gates directly yields 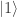 . Applying Hadamard gates to all
. Applying Hadamard gates to all  qubits yields
qubits yields


 :
:

 . By measuring the final state, we can read out
. By measuring the final state, we can read out 


 . The function is constant if
. The function is constant if  , and balanced if
, and balanced if  (equivalently,
(equivalently,  , where
, where 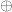 denotes addition modulo 2). Determining whether
denotes addition modulo 2). Determining whether  . This can also be viewed as a quantum XOR game: if the result is 0, then
. This can also be viewed as a quantum XOR game: if the result is 0, then 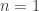 case of the Deutsch-Jozsa algorithm, to gain some intuition about how quantum algorithms work.
case of the Deutsch-Jozsa algorithm, to gain some intuition about how quantum algorithms work. 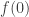 and
and 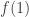 . There is no way around this. Quantum mechanically, we can do better. To begin, we need to “promote” the function
. There is no way around this. Quantum mechanically, we can do better. To begin, we need to “promote” the function 




 regardless of the value of
regardless of the value of  .
.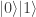 . Then we perform the following steps:
. Then we perform the following steps: .
. .
. .
.

 appears as a phase. The key identity is
appears as a phase. The key identity is
 . The state after applying the oracle can be rewritten as
. The state after applying the oracle can be rewritten as




 of the first qubit. To read out this information, we apply a Hadamard gate to the first qubit and then measure it in the computational basis. This is an example of an interferometric measurement scheme, a standard method for extracting the coefficient of a state in a given basis; you will encounter this technique in many other contexts as well.
of the first qubit. To read out this information, we apply a Hadamard gate to the first qubit and then measure it in the computational basis. This is an example of an interferometric measurement scheme, a standard method for extracting the coefficient of a state in a given basis; you will encounter this technique in many other contexts as well.



 (the function is constant), we will certainly measure
(the function is constant), we will certainly measure 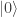 .
. (the function is balanced), we will measure
(the function is balanced), we will measure  case, the classical oracle must be replaced by a quantum oracle
case, the classical oracle must be replaced by a quantum oracle 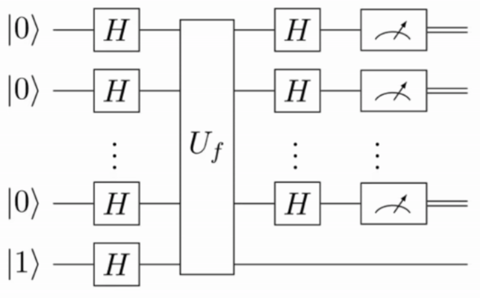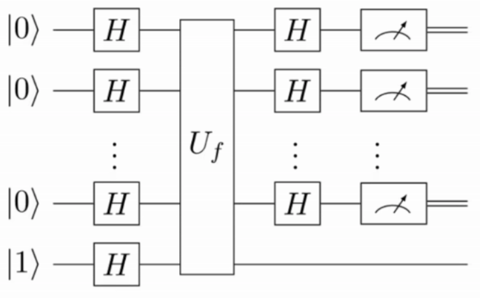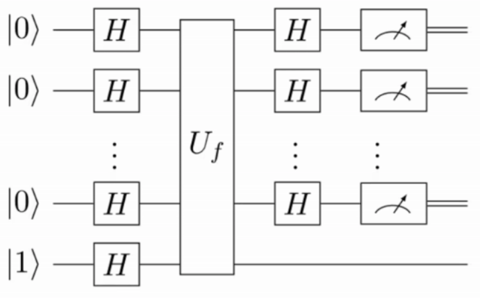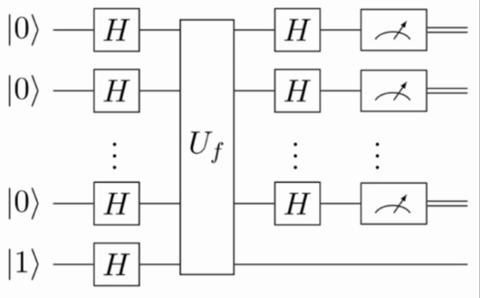

 is an
is an 
 is unitary.
is unitary. the image
the image  is again a computational-basis vector, and distinct input basis vectors have distinct images because
is again a computational-basis vector, and distinct input basis vectors have distinct images because  is a bijection on ${0,1}$. Hence the set of images of the computational basis is another orthonormal basis of the Hilbert space. A linear map that sends an orthonormal basis to an orthonormal basis preserves inner products and therefore is unitary. Thus
is a bijection on ${0,1}$. Hence the set of images of the computational basis is another orthonormal basis of the Hilbert space. A linear map that sends an orthonormal basis to an orthonormal basis preserves inner products and therefore is unitary. Thus  since
since  , so
, so  , and a permutation matrix with real entries has its inverse equal to its adjoint; either way
, and a permutation matrix with real entries has its inverse equal to its adjoint; either way  .
. .
. ,
, .
. .
. .
.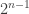 times in the worst case. The Deutsch-Jozsa algorithm solves the problem with only one evaluation of the oracle, compared to the exponentially growing number of evaluations required by a classical algorithm. The quantum algorithm achieves this exponential speedup by leveraging quantum superposition and interference.
times in the worst case. The Deutsch-Jozsa algorithm solves the problem with only one evaluation of the oracle, compared to the exponentially growing number of evaluations required by a classical algorithm. The quantum algorithm achieves this exponential speedup by leveraging quantum superposition and interference.
 be a positive integer, and let
be a positive integer, and let  of
of  ). The notation
). The notation  denotes the set of invertible elements in
denotes the set of invertible elements in  or simply
or simply 

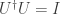 , all eigenvalues of
, all eigenvalues of  with
with  . Expressing
. Expressing 
 . The task is to estimate
. The task is to estimate  ,
, operations can be implemented for arbitrary non-negative integer
operations can be implemented for arbitrary non-negative integer  . The goal is to estimate
. The goal is to estimate  .
.
 can be omitted, as it contributes only a trivial phase factor of
can be omitted, as it contributes only a trivial phase factor of  , its action on
, its action on  (with
(with 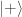 the control qubit) is:
the control qubit) is:

 .
.
 therefore remains unchanged and can be reused in subsequent steps.
therefore remains unchanged and can be reused in subsequent steps.
 .
. .
.
 denotes the binary representation of the integer
denotes the binary representation of the integer  in the first register, apply the controlled-
in the first register, apply the controlled-
 , this becomes:
, this becomes:
 ) on the first register to extract the phase information:
) on the first register to extract the phase information:

 are the binary digits of
are the binary digits of 